基于Spark NoSQL的實時數據處理實踐(下) 數據處理服務構建與優化
在上一部分探討了基于Spark與NoSQL數據庫的實時數據采集與存儲架構后,本部分將聚焦于核心的數據處理服務。數據處理服務是整個實時流水線的大腦,負責將原始數據轉化為有價值的業務洞察。
一、數據處理服務的核心架構
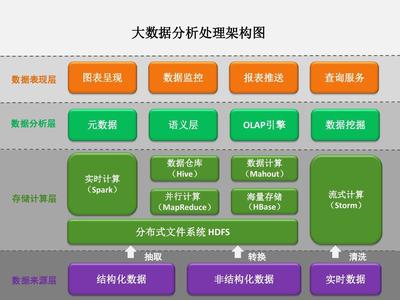
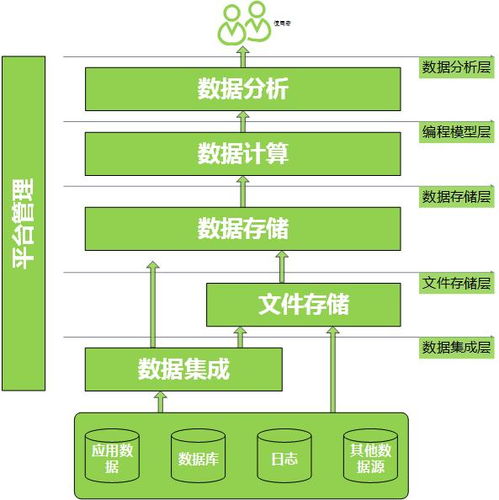
一個健壯的數據處理服務通常構建于Apache Spark Streaming或Structured Streaming之上,并與NoSQL數據庫深度集成。其核心模塊包括:
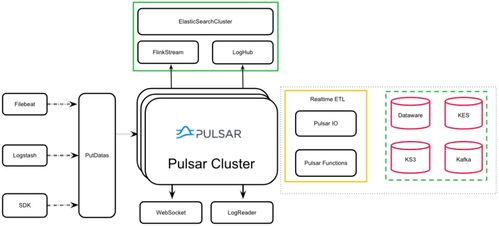
- 流數據接入層: 從Kafka、Pulsar等消息隊列中持續消費原始數據流。利用Spark的
readStreamAPI,可以輕松對接多種數據源。 - 核心處理引擎: 這是服務的核心,利用Spark SQL、DataFrame API及用戶自定義函數(UDF/UDAF)實現業務邏輯。處理模式包括:
- 數據清洗與標準化: 過濾無效數據、解析復雜格式(如JSON嵌套)、統一數據編碼。
- 實時聚合與統計: 基于滑動窗口或滾動窗口,計算每分鐘的訂單量、用戶活躍度等關鍵指標。
- 事件模式匹配: 使用Spark的“狀態流處理”功能,檢測復雜的用戶行為序列(如“瀏覽-加入購物車-下單”)。
- 流-流/流-批Join: 將實時流與存儲在NoSQL中的維度表(如用戶畫像)或另一個流進行關聯,豐富數據上下文。
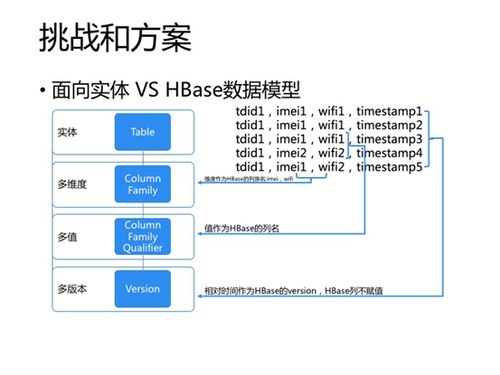
- 狀態管理與容錯: 利用Spark的檢查點(Checkpointing)機制和NoSQL(如Cassandra、HBase)的持久化能力,可靠地保存計算中間狀態,確保Exactly-Once語義和故障后快速恢復。
- 結果輸出與服務層: 將處理結果寫回NoSQL數據庫(供下游查詢),或同步至OLAP系統、推送至實時儀表盤。可封裝為低延遲的RESTful或gRPC API服務,直接供前端應用調用。
二、與NoSQL數據庫的協同實踐
- 作為維表(Lookup Table): 將HBase或Cassandra中的靜態/準靜態數據(如商品信息、用戶資料)廣播或定期加載到Spark中,用于流數據的實時關聯查詢,極大提升處理效率。
- 作為結果存儲與狀態后端:
- 實時指標存儲: 將聚合結果(如計數器、排行榜)寫入Redis或Cassandra,利用其高性能讀寫特性,支撐實時查詢。
- 狀態持久化: 對于復雜的、需要跨批次維護狀態的應用(如會話超時),可將狀態持久化到具備TTL功能的NoSQL中,由Spark進行管理,增強系統的可擴展性與可靠性。
- 使用Spark NoSQL Connector進行高效讀寫: 利用為特定NoSQL優化的連接器(如
spark-cassandra-connector、HBase-Spark),可以:
- 并行讀寫,充分利用集群資源。
- 下推謂詞過濾(Predicate Pushdown),減少不必要的數據傳輸。
- 自動進行分區映射,優化數據本地性。
三、性能優化與最佳實踐
- 微批處理與吞吐量調優: 合理設置Structured Streaming的觸發間隔(
trigger)和處理最大偏移量,在延遲與吞吐量之間取得平衡。 - 資源動態分配: 結合Spark的動態資源分配(Dynamic Allocation)功能,根據數據流量自動調整Executor數量,實現資源高效利用。
- 序列化與數據結構優化: 使用Kryo序列化,并盡量使用Spark原生的
Dataset[Case Class]而非RDD,以利用Catalyst優化器和鎢絲計劃(Tungsten)的二進制內存管理優勢。 - 處理邏輯異步化: 對于需要調用外部服務(如風控接口)的環節,使用
mapPartitions結合異步HTTP客戶端,避免阻塞整個流水線。 - 監控與告警: 密切監控Spark UI中的批處理時間、調度延遲、背壓(Backpressure)指標,以及NoSQL的讀寫延遲。設置閾值告警,確保服務SLA。
四、典型應用場景示例
以“實時反欺詐系統”為例:
- 交易流進入Spark Streaming。
- 處理服務實時從Redis中查詢該用戶近期行為畫像(維表關聯)。
- 基于規則引擎(可集成在UDF中)或簡易的實時模型,對交易進行評分。
- 將高風險交易實時寫入HBase供審核,并將用戶風險標簽更新回Redis(狀態/結果存儲)。
- 聚合統計各渠道的欺詐率,寫入Cassandra并同步至實時大屏。
###
構建基于Spark NoSQL的實時數據處理服務,關鍵在于充分發揮Spark在復雜流計算上的強大能力,同時利用NoSQL數據庫在靈活模型、高并發讀寫和持久化方面的優勢,實現兩者間的無縫協同與性能優化。通過分層的服務設計、精細的狀態管理和持續的監控調優,最終打造出穩定、高效且能快速響應業務變化的實時數據處理能力。
如若轉載,請注明出處:http://m.pcqcd.cn/product/76.html
更新時間:2026-04-13 19:33:54